La inteligencia artificial genera un vocabulario propio que crece a un ritmo vertiginoso. Este glosario recoge 50 términos esenciales que todo profesional técnico debería conocer para navegar el ecosistema actual. Los términos están agrupados por categorías para facilitar su consulta.
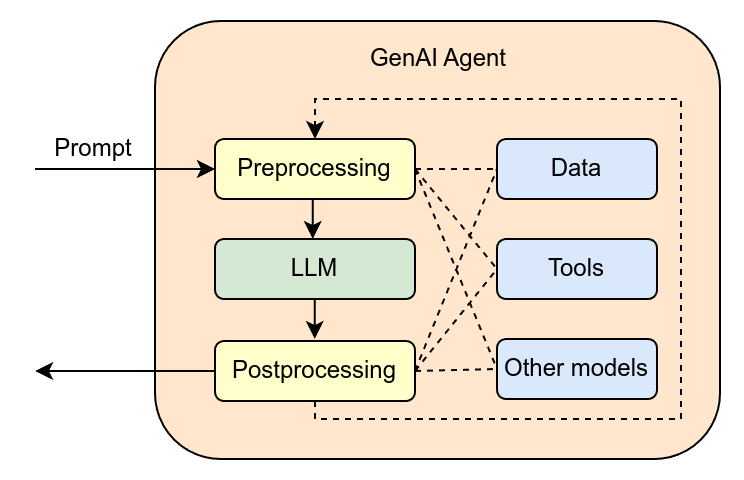
1. Agente (AI Agent): Sistema autónomo que utiliza un LLM para razonar, dispone de herramientas para interactuar con el mundo y sigue un bucle observación-acción-reflexión para completar tareas.
2. Modelo de Lenguaje Grande (LLM): Red neuronal entrenada con grandes volúmenes de texto que predice la siguiente palabra (token) en una secuencia. La base de la mayoría de sistemas de IA generativa actuales.
3. Token: Unidad mínima de procesamiento del lenguaje. Puede ser una palabra, parte de una palabra o un carácter. Los modelos cobran por tokens procesados.
4. Prompt: Instrucción o entrada textual que se proporciona a un LLM para obtener una respuesta. La calidad del prompt determina la calidad de la salida.
5. Inferencia: Proceso mediante el cual un modelo entrenado genera una salida a partir de una entrada. Contrasta con el entrenamiento, que es la fase de aprendizaje.
6. Fine-Tuning: Proceso de entrenar adicionalmente un modelo pre-entrenado con datos específicos de un dominio para adaptarlo a tareas concretas.
7. Alucinación: Fenómeno por el cual un LLM genera información falsa o incorrecta con apariencia de veracidad. Ocurre porque el modelo prioriza la coherencia estadística sobre la veracidad factual.
8. Temperature: Parámetro que controla la aleatoriedad de las salidas del modelo. Baja (0.0–0.2) produce respuestas deterministas; alta (0.8–1.0) aumenta la creatividad.
9. Embedding: Representación vectorial de texto en un espacio continuo. Los embeddings capturan relaciones semánticas y permiten búsquedas por similitud.
10. Context Window: Cantidad máxima de tokens que un modelo puede procesar en una sola interacción. Ventanas grandes permiten procesar documentos completos.
11. Multi-Agent System (MAS): Sistema compuesto por múltiples agentes que colaboran, compiten o se coordinan para resolver tareas complejas. Inspirado en colonias de hormigas o abejas.
12. Orquestador (Supervisor Agent): Agente central que descompone tareas, las asigna a subagentes especializados y sintetiza los resultados. Patrón común en sistemas multi-agente.
13. Tool (Herramienta): Función o API que un agente puede invocar para interactuar con el mundo exterior (búsqueda web, ejecución de código, acceso a base de datos).
14. Function Calling: Mecanismo por el cual un LLM selecciona y llama a una función definida externamente a partir de una descripción en JSON.
15. Bucle Agente (Agent Loop): Ciclo continuo de percibir → razonar → actuar → observar → ajustar. El núcleo de cualquier sistema agente.
16. RAG (Retrieval-Augmented Generation): Técnica que combina recuperación de información (búsqueda) con generación de texto. Permite a un LLM responder basándose en documentos externos.
17. Agente Conversacional: Agente diseñado específicamente para mantener diálogos naturales con humanos, utilizando gestión de estado, reconocimiento de intención y generación contextual de respuestas.
18. Harness (Arnés): Infraestructura que envuelve a un agente, proporcionándole el bucle de ejecución, las herramientas, la gestión de estado y la conexión con el LLM.
19. Subgraph: En LangGraph, un subgrafo que encapsula la lógica de un agente especializado. Permite reutilización, aislamiento de contexto y mejor observabilidad.
20. Checkpointer: Mecanismo que guarda el estado de ejecución de un agente, permitiendo pausar, reanudar o depurar flujos de trabajo complejos.
21. MCP (Model Context Protocol): Protocolo abierto para la comunicación entre agentes y fuentes de contexto. Permite que los agentes accedan a herramientas y datos de forma estandarizada.
22. A2A (Agent-to-Agent): Protocolo de comunicación directa entre agentes, permitiendo delegación de tareas, intercambio de información y coordinación descentralizada.
23. Patrón Secuencial: Agentes que trabajan en cadena: la salida de uno es la entrada del siguiente. Útil para pipelines de procesamiento.
24. Patrón de Votación: Múltiples agentes generan respuestas independientes y un mecanismo de votación selecciona la mejor. Mejora la precisión en tareas críticas.
25. Message Bus (Bus de Mensajes): Arquitectura donde los agentes se comunican a través de un canal compartido (publicar-suscribir). Ideal para sistemas orientados a eventos.
26. Shared State (Estado Compartido): Patrón de coordinación donde los agentes leen y escriben en un «tablero» común. Elimina cuellos de botella pero requiere reglas de terminación claras.
27. KYA (Know Your Agent): Concepto de identidad verificable para agentes, similar al KYC bancario. Permite establecer confianza y responsabilidad en sistemas multi-agente abiertos.
28. Pruebas de Conocimiento Cero (ZK Proofs): Técnica criptográfica que permite verificar que una salida de IA es correcta sin revelar los datos subyacentes. Clave para la confianza en agentes autónomos.
29. Descoordinación (Miscoordination): Fallo en la coordinación entre agentes debido a comunicación deficiente, objetivos en conflicto, contención de recursos o dependencias enredadas.
30. Graceful Extensibility: Capacidad de un sistema para adaptarse antes de saturarse. En agentes, implica que otros agentes expandan su capacidad para compensar a los que están cerca del límite.
31. Evals (Evaluaciones): Conjunto de pruebas y métricas para medir el rendimiento de un agente. Incluyen precisión, latencia, tasa de error y tasas de regeneración.
32. Señal Explícita: Métrica objetiva y verificable (tasa de error, latencia, coste). Fácil de medir pero no captura calidad semántica.
33. Señal Implícita: Indicador semántico más difícil de detectar (frustración del usuario, rechazos, jailbreaking). Más valiosa que las señales explícitas para entender el comportamiento real.
34. Autodiagnóstico (Self-Diagnostic): Técnica donde el agente informa proactivamente de incidencias a sus creadores mediante una herramienta «report». Bajo esfuerzo, alto impacto.
35. Tasa de Regeneración: Frecuencia con la que se solicita regenerar una respuesta. Una tasa alta indica problemas de calidad no capturados por otras métricas.
36. Tracing (Trazado): Registro detallado de cada paso que da un agente: llamadas a herramientas, decisiones intermedias, tiempos de ejecución. Esencial para depuración y auditoría.
37. Prompt Injection: Técnica de ataque donde un usuario malicioso introduce instrucciones en la entrada para alterar el comportamiento del modelo. Principal vector de vulnerabilidad en agentes.
38. Vector Database: Base de datos especializada en almacenar y buscar embeddings vectoriales. Fundamental para RAG y búsqueda semántica.
39. Hybrid Search: Combinación de búsqueda por palabras clave y búsqueda vectorial. Ofrece mejores resultados que cualquiera de las dos por separado.
40. Context Graph: Grafo de conocimiento que conecta entidades, documentos y relaciones. Permite a los agentes navegar contextos complejos de forma estructurada.
41. Cuantización: Técnica que reduce la precisión numérica de los pesos de un modelo para disminuir su tamaño y requisitos de hardware, a costa de una ligera pérdida de calidad.
42. Pricing Híbrido: Modelo de precios que combina una tarifa base fija con costes por uso. El modelo dominante en productos de IA (56% de adopción entre líderes del sector).
43. Value-Based Pricing: Estrategia que fija el precio según el valor percibido por el cliente, no según el coste de los recursos. Ejemplo: cobrar por informes generados, no por tokens consumidos.
44. Credits (Créditos): Capa de abstracción que empaqueta funcionalidades en unidades de crédito. Permite cambiar la combinación de servicios sin alterar los precios visibles al cliente.
45. GPU Accesibilidad: Problema creciente de escasez de GPUs para entrenamiento e inferencia de modelos. Impulsa la adopción de modelos locales y la optimización de recursos.
46. Estrategia vs. Eficacia Operativa: La eficacia operativa es hacer las cosas bien (mejores prácticas). La estrategia es hacer cosas diferentes — elegir actividades únicas que te diferencien de la competencia.
47. Trade-off (Compensación): Decisión estratégica fundamental: elegir qué NO hacer. Sin renuncias no hay estrategia sostenible.
48. Liderazgo vs. Gestión: La gestión mantiene sistemas; el liderazgo crea cambios. El liderazgo implica asumir responsabilidad sin esperar autorización.
49. Value Proposition: Propuesta de valor que responde a: «¿Para quién es? ¿Qué cambio buscamos generar?» Debe ser específica y centrada en un segmento mínimo viable.
50. Estado de Flow: Estado óptimo de conciencia caracterizado por absorción total, distorsión del tiempo y «esfuerzo sin esfuerzo». Se alcanza cuando el desafío supera ligeramente la habilidad actual.
Este glosario sintetiza conceptos de todas las charlas y cursos mencionados en la Campaña IA 2026. Las fuentes completas están disponibles en cada artículo temático de la serie.
Atribución: Adaptación y síntesis de materiales del canal AI Engineer, AI Agents Course, Harvard Business Review, Seth Godin, Steven Kotler y otras fuentes citadas a lo largo de la campaña.